CodePipeline Deployment with Terraform
It’s easy to understand how to use Terraform to set up a container orchestration platform, such as AWS Elastic Container Service (ECS). You basically read the documentation, figure out the pieces involved, and put them together like LEGO.

Terraform supports all key ECS-related resources to get set up. You simply need to put the pieces together.
What’s unclear though is how to deploy updated Docker images for your services once set up, particularly stateful services that manage their own schema. Furthermore, how can you do that as part of a Continuous Delivery (CD) pipeline? For example, in the pipeline below, how can we use Terraform in the Deploy step to deploy the latest Docker image built in the Build step, with zero-downtime, in an automated fashion, even if the new image requires a schema update? That part is not so clear.

On code commit (Source), build a new Docker image (Build), and deploy it onto ECS (Deploy), taking care of any potential schema updates along the way.
When we were planning our migration of services built on Ruby on Rails, Node.js, and Scala onto an orchestration platform, such as AWS ECS, we were left with a set of questions we could not find clear answers for:
- How can we use Terraform in our Continuous Delivery (CD) pipeline?
- If we use Terraform to provision our services, how will we deploy subsequent updates which can include database schema updates?
- How can we limit the permissions required by Terraform in our CD for code updates only, rather than something like database configuration updates?
- And how can we achieve this while maintaining blue-green deployment?
We started thinking maybe Terraform can’t do this; maybe Terraform isn’t the right tool for the job. But that was hard to accept. Terraform got us so close! It could get our entire service up and running on ECS, all in a single terraform apply, yet for incremental code and schema updates, we had to use a different tool? That can’t be true, right?
So we dug further, and with a bit of ingenuity, we figured out how to effectively control Terraform’s execution for our needs, and were able to answer our questions. In this post, I want to share with you how we did it and what we learnt along the way.
This post assumes you have a basic understanding of Terraform. While the examples are with AWS ECS (since we at ACL use ECS), the core learnings are not related to ECS and can be used generally with Terraform.
AWS Elastic Container Service (ECS)
You may know what Terraform is, but what is AWS ECS? It is a container orchestration platform, where you declare the Docker containers you want to run, and ECS figures out the best way to run them for you. It bares resemblance to Terraform in that you declare what you want and ECS takes care of making it happen. While there is a lot more to ECS, for the purpose of this post, what we need to know about ECS is that it allows us to define the containers we want to run (i.e. an ECS Task) and how to run them (i.e. an ECS Service). If you are using Kubernetes, you may be able to mentally translate this post by thinking about Kubernetes pods and services instead.
Imperative vs. Declarative
For the most part, it’s easy to use Terraform and ECS together to get up and running. There is plenty of documentation and examples to replicate. However, it becomes challenging when you want more granular control over how your infrastructure and containers come into existence. There are scenarios where you do not simply want to declare your needs, but you want to specify how to fulfill your needs. This is particularly relevant for stateful services. For example:
- When provisioning a database, you may want to run a “seed” script to set up the initial table definitions, stored procedures, etc. so that the database is ready from the start for your application’s logic.
- When deploying code updates, you may need to perform a “schema update” beforehand.
- When applying updates using a Continuous Deployment (CD) pipeline, you probably want to limit your CD’s scope of impact to updating containers only.
- Lastly, you want all of this done in a particular order, such that if anything is to fail, deployment halts so you can debug before proceeding.
How to achieve this with Terraform is not trivial, and requires a bit of trickery. In particular, it requires using Terraform’s null_resource resources, defining dependencies explicitly using depends_on, and scoping your plan /apply executions with targets.
null_resource — Execute Arbitrary Logic in Terraform
Despite Terraform’s large number of providers, there are certain scenarios where you need to execute your own logic. This is where the null_resource comes in handy. Taken straight from the documentation:
A
null_resourcebehaves exactly like any other resource, so you configure provisioners, connection details, and other meta-parameters in the same way you would on any other resource.
For example, if you want to provision a seeded database, you can create a null_resource to execute the seeding logic after the database is created:
variable "password" { default = "password123" }resource "aws_db_instance" "example" {
allocated_storage = 10
storage_type = "gp2"
engine = "postgres"
instance_class = "db.t2.micro"
name = "example"
username = "user"
password = "${var.password}"
}resource "null_resource" "seed" {
provisioner "local-exec" {
command = "PGPASSWORD=${var.password} psql --host=${aws_db_instance.example.address} --port=${aws_db_instance.example.port} --username=${aws_db_instance.example.username} --dbname=${aws_db_instance.example.name} < seed.sql"
}
}
In this simple example, the local-exec provisioner of the null_resource is executed in the local environment where Terraform is running, after the database is created. It will execute psql to seed the database with the seed.sql script. In practice, you can use other provisioners if necessary and more complex scripts to achieve the same thing, but the key point remains the same: using a null_resource, you can execute arbitrary logic as part of a regular Terraform execution.
In fact, with a null_resource, you can inject any arbitrary logic, at any point of a Terraform execution, to control what is happening. That gives you a tremendous amount of freedom and ability to customize your Terraform executions without requiring custom providers. But how did Terraform know to execute that logic after database creation? To understand that, you need to understand how Terraform works.
Taking Control of the Resource Graph
An important trait of Terraform’s execution is how it creates a “Resource Graph” to perform its work. Citing from the introduction:
Terraform builds a graph of all your resources, and parallelizes the creation and modification of any non-dependent resources. Because of this, Terraform builds infrastructure as efficiently as possible, and operators get insight into dependencies in their infrastructure.
This graph is what allows us to simply declare what we want provisioned and let Terraform take care of it. By default, Terraform parallelizes whatever it can, unless there is a dependency that prevents it from doing so. Thus, to control Terraform’s execution order, we need to think about the underlying dependency graph. With the appropriate dependency setup, we can do tasks in parallel or in sequence. To explicitly define sequential dependencies, you can use the depends_on property available to all Terraform resources. For example, by default the following three resources will be created in parallel:
resource "null_resource" "first" {
provisioner "local-exec" {
command = "echo 'first'"
}
}resource "null_resource" "second" {
provisioner "local-exec" {
command = "echo 'second'"
}
}resource "null_resource" "third" {
provisioner "local-exec" {
command = "echo 'third'"
}
}

Underlying dependency graph shows parallel execution (simplified view)
However, we can create them sequentially if we configure the depends_on property appropriately:
resource "null_resource" "first" {
provisioner "local-exec" {
command = "echo 'first'"
}
}resource "null_resource" "second" {
depends_on = ["null_resource.first"]
provisioner "local-exec" {
command = "echo 'second'"
}
}resource "null_resource" "third" {
depends_on = ["null_resource.second"]
provisioner "local-exec" {
command = "echo 'third'"
}
}

Underlying dependency graph shows sequential execution (simplified view)
You’re probably starting to see the solution now for how we can deploy updates to stateful services using Terraform: use null_resources with the appropriate depends_on dependencies to have sequential execution for key steps. In particular:
- Define new containers to be deployed (i.e. update your
aws_ecs_task_definitionresources) - Update the database schema, if necessary (i.e. run
null_resourcewith your schema update script, with adepends_onon theaws_ecs_task_definitionof step #1) - Deploy the new containers (i.e. update
aws_ecs_serviceto use your new containers from step #1, with adepends_onon thenull_resourcefrom step #2)
This ensures our database schema is up-to-date before the new code is deployed. Hoorah!
We’re getting close, but something is missing. For a reasonably sophisticated service, you do not want to execute terraform apply on everything during a code deployment. For example, your Terraform logic may set up DNS entries, set up Redis, set up load balancers, etc. which you do not want touched during a code deployment. It’d be too much change at once, it’d mix together infrequently changed resources (e.g. DNS) with frequently changed resources (e.g. application logic), and it’d require your CD to have a large set of permissions. To reduce that scope, we need to use another feature: Terraform’s ability to -target executions.
Targeted Changes
As your infrastructure gets more sophisticated, and the number of Terraform resources rises, it becomes risky to have Terraform simply apply everything in an automated fashion. You want to reduce the scope of an apply. Fortunately, Terraform has addressed this scenario by giving you the option to -target a particular resource during an execution.
The
-targetoption can be used to focus Terraform's attention on only a subset of resources.
We had long used this when we wanted to target a single resource; however, this was not viable when we needed to deploy groups of resources at the same time (e.g. ECS Task, ECS Service, null_resource, etc.). Fortunately, we realized we can aggregate many targets into one by combining null_resource and depends_on together. For example:
resource "null_resource" "deployment" {
triggers {
revision = "${var.git_revision}"
}
depends_on = [
"aws_ecs_service.application",
"aws_ecs_task_definition.application",
"null_resource.migrate"
]
}Thus when we can execute terraform apply -target=null_resource.deployment, due to the Resource Graph related to this resource, it updates all associated deployment resources as well. In this example, it makes sure to update only our aws_ecs_task_definition, aws_ecs_service, and run any schema updates via null_resource.migrate. Using a targeted resource, we felt comfortable getting our CD to apply Terraform without risking any unexpected changes taking place.
With these three key pieces together, I can now share with you how ACL has set up its deployment using Terraform.
Putting it all Together — Deploying using Terraform
At ACL, we use AWS CodePipeline for deployments. While I’ll explain our solution using CodePipeline, this solution is possible on any Continuous Delivery tool (e.g. Jenkins). Below is an example service we deploy using Terraform in our pipeline:
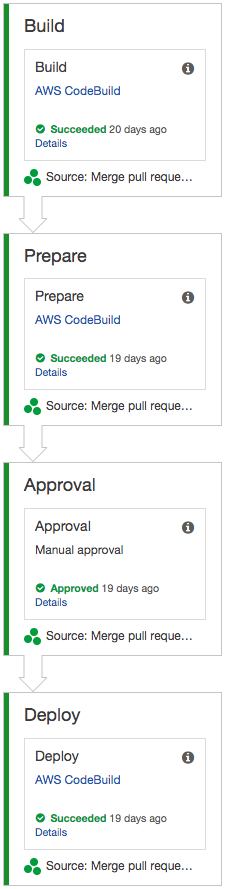
- Build: we create the service’s Docker image and push to AWS ECR.
- Prepare: we use Terraform with the target
null_resource.prepareto create new ECS Tasks for our service, but not yet update the associated ECS Service to use them. - Approve: we prepare everything, but wait for an explicit approval step to deploy. This gives development teams control, and our compliance team a clear audit trail of who authorized a deploy.
- Deploy: we use Terraform with the target
null_resource.deployto run our schema update scripts (if any), and update our ECS Service to use the new ECS Tasks.
As the pipeline demonstrates, we use various null_resources to control the execution of Terraform for deployment. Our pipeline’s execution environment is a Docker image we’ve built purely for deployment purposes. It has Terraform installed, along with other languages and tools we’ll need for our null_resources’ local-exec provisioners to execute successfully. For example, we’ve written a script in Ruby to schedule one-off ECS tasks, which we use to run our schema update scripts. The following is the null_resource.migrate resource that uses it and runs as part of deployment.
resource "null_resource" "migrate" {
triggers {
revision = "${var.git_revision}"
database = "${aws_db_instance.application.address}"
}
depends_on = ["aws_ecs_task_definition.application"]
provisioner "local-exec" {
command = <<EOS
ruby ./ecs_task_runner.rb
-f ${aws_ecs_task_definition.application.family}
-v ${aws_ecs_task_definition.application.revision}
-e .ecs/db_migrate.sh
EOS
}
}This ability to mix in custom logic and execute them at the right time gives us significant control over how we want our deployments to be done. It’s also why we do not feel compelled to look for a separate deployment tool yet, since we can customize Terraform for our needs.
Additional Learnings
Along the way, we learnt some additional details I thought I’d share in case you pursue this path:
- Non-scripting languages, such as Scala, may require a separate ECS Task to run your migration scripts. We use Play framework, and the ECS Task that runs the application does not have the code to perform a schema migration, so we have to create a separate ECS Task to run migration scripts on.
- Our scripts that ran ECS Tasks inside
local-execprovisioners were first made with the AWS CLI; unfortunately, we learnt that the AWS CLI will timeout after 10 minutes. We had to rewrite them in Ruby to support a higher limit. - We made a conscious decision to differentiate our Continuous Integration pipeline (CI) from our Continuous Delivery pipeline (CD). CI is done on a separate 3rd-party platform dedicated for CI, where teams can quickly and easily run their test suites, while CD is done on AWS CodePipeline, where our infrastructure team uses it to deploy code into production in a secure and compliant manner.
Conclusion
There you have it. You can use Terraform to blue-green deploy your services onto ECS with a high-level of control. No need for a separate tool. It does not mean Terraform should be the deployment tool for all scenarios. Rather, it means Terraform can be the deployment tool until a real need arises for a separate tool.
In fact, by keeping it simple and using Terraform in AWS CodePipeline, we can rely on AWS’s secure and compliant services, rather than relying on less-secure third-party CI/CD services. That has drastically shortened our delivery timeline, and has opened up our infrastructure team’s capacity to focus on other challenges. The more AWS manages for us, the better!
I hope this post explained how you can control Terraform more granularly. If you have any questions or tips of your own, please do share in the comments. Thank you for reading and commenting!